"관광객수, 블로그 게시글수와 정비례"···상관계수 0.81(뉴시스, 2020.10.28.)를 읽고
1. 기사의 핵심
"지난해 1월부터 올해 8월까지 네이버 블로그 사이트에서 검색어 '태화강 대공원'과 '태화강 국가정원'으로 수집한 1만5066건의 데이터를 분석한 결과, 올해 1~8월 해당 검색어가 포함된 네이버 블로그 게시글 수는 전년 같은 기간 (3634)의 배인 7308건으로 늘어났다.
김 박사는 블로그 게시글 수와 관광객 수 사이에는 상관계수 0.81로 상관관계가 높다고 강조했다. 선형회귀모형계수 55.9로, 블로그 수가 100개 증가하면 관광객 수가 약 5600명 증가한다는 설명이다."
2. 상관계수가 뭐냐?
김 박사는 상관계수가 0.81이라서 높다고 강조를 하셨는데,
상관계수 0.81이 뭐고 왜 높은 것인지 나는 모르겠어서 상관계수에 대해 공부를 해보아야 한다.
하지만 상관계수를 알아보기 위해서는 평균, 편차, 분산, 표준편차, 공분산에 대해서 먼저 알아보아야 한다.
평균(average)
예시와 함께 쉽고 간단하게 알아보자.
자, 먼저 평균이다.
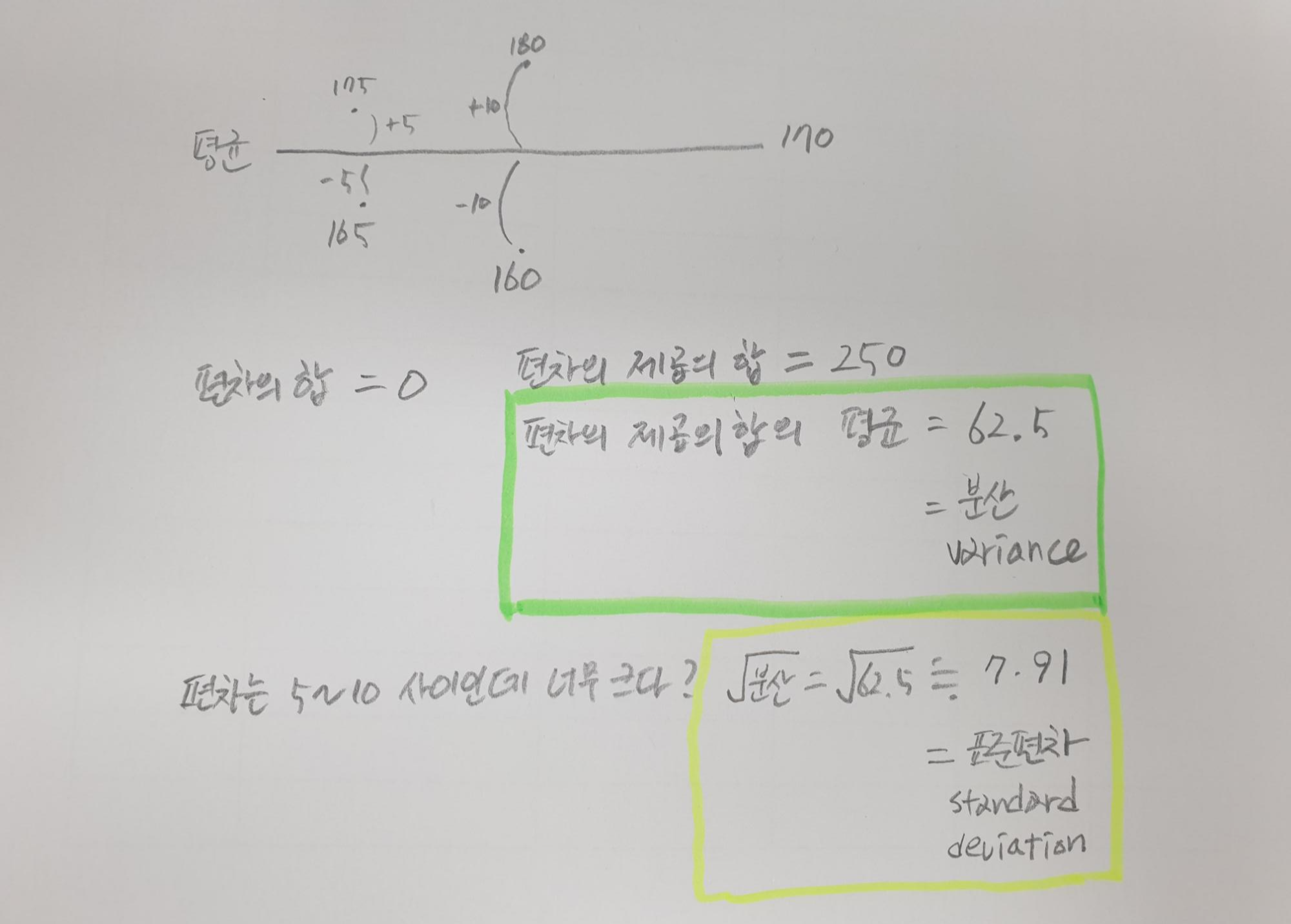
키가 각각 175,165,180,160 cm인 4명의 사람이 있다고 가정을 해보자.
이 때 평균 키는? 간단하다. 키를 모두 더하고 4를 나눈 숫자, 170이 나온다.
편차
그러면 이 평균 키 170cm를 기준으로
각자는 +5, -5, +10, -10cm만큼의 차이를 갖고 있다. 이것이 편차이다.
여기까지 매우 쉽다.
분산
그러면 이 편차는 평균적으로 어느정도 되는가?
편차를 다 더하면 공교롭게도 0이라, 평균을 구할 수가 없다....
그러면 어떻게 해야 되나?
편차를 제곱을 해서 평균을 내보자. 제곱을 하면 모두 양수가 되니까
이것이 바로 분산이다.
(25+25+100+100) /4 = 62.5
표준편차
위 예시에 따라 편차를 제곱한 것의 합을 4로 나누었더니, 62.5가 나온다.
그런데 편차는 5에서 10 사이였는데 62.5라니 숫자가 너무 큰 것 아닌가 싶다.
그럼 이 분산에 루트(√)를 씌워보자. 약 7.91이 나온다.
아 편차들이 대충 이정도에서 분포하겠구나.
분산에 루트를 씌운 값. 이것이 표준편차이다.
☞ 여기서 똑똑한 사람은 '평균에서 멀리 떨어져있으면 표준편차가 크겠구나'라고 예측할 수 있다
공분산
표준편차까지 왔다.
이제 공분산만 보고 나면 상관계수에 닿을 수 있다!
아까 예를 들었던 키가 각각 175,165,180,160 cm인 4명의 사람에 대해서
몸무게가 각각 75, 70, 95, 72 kg라고 가정을 해보자.
그러면 아까와 동일하게 평균이 나오고(78), 평균에 따른 각각의 편차가 나온다.
아까는 표준편차를 구하기 위해 편차의 제곱을 평균냈다면,
이번에는 이 두 데이터의 분산을 구하기 위해, 각 데이터의 편차를 곱해보자.
키 175, 몸무게 75인 사람은 키는 편차가 +5, 몸무게는 편차가 -3이니 곱하면 -15가 나온다.
나머지 네 분도 동일하게 계산해서 이것을 모두 더해주면 255가 나오고,
이것의 평균이 63.75가 나오는데 이것이 바로 공분산이다.

상관계수
조금 전에 분산이 너무 커서 루트를 씌운 표준편차를 기억하는가?
공분산도 구해놓고 보니까 너무 크다...
그리하여 공분산을 데이터A(키)의 표준편차와 데이터B(몸무게)의 표준편차의 곱으로 나누어 준 것이
바로 상관계수이다.
상관계수는 -1에서 1사이 값을 갖는다.

3. 상관계수가 무슨 의미냐?
앞서 상관계수를 도출하는 방법을 알아보았는데,
상관계수는 두 변수가 무슨 관계가 있는지를 보여준다.
먼저 우리는 상관계수를 구하기 전에 공분산을 구했었는데,
공분산은 두 편차를 곱해준 값의 합을 평균내는 방식으로 구했었다.
두 편차가 각각 (+),(+) 관계이거나, (-),(-) 관계이거나 더한 값이 양의 값이면 공분산이 (+)이고
반대의 경우는 (-) 공분산일 것이다.
즉, 두 데이터의 관계가 비슷하게 흐르면 플러스, 상호 반대적으로 흐르면 마이너스가 나오는 것이고
공분산을 보기좋게 줄여놓은 상관계수는 당연히 1에 가까울수록 둘은 비슷하고
-1에 가까울수록 둘은 반대로 흐르는 경향이 있다고 보는 것이다.
자, 이제 김 박사님이 상관계수가 0.81로 크다고 한 말의 의미를 이제는 알 수 있게 되었다.
-1에서 1사이의 값이 나오는 상관계수인데, 1과 거의 근접한 0.81이니 큰 숫자이고
1에 가까우니 블로그 수와 관광객 수는 정(正)의 관계가 있다고 볼 수 있는 것이다.

4. 참고사항
상관계수는 그리스 문자 "ρ"(로)으로 나타낸다.
표준편차, 공분산은 시그마∂로 나타낸다.
상관계수AB는 공분산AB를 표준편차A와 표준편차B의 곱으로 나눈 값이며
이는 즉, 공분산AB는 상관계수AB와 표준편차A와 표준편차B의 곱이다.

참고기사: newsis.com/view/?id=NISX20201028_0001213627&cID=10814&pID=10800
"관광객수, 블로그 게시글수와 정비례"···상관계수 0.81
[울산=뉴시스] 조현철 기자 = 울산연구원 김상락 박사는 28일 '울산경제사회 브리프'를 통해 "블로그 게시글이 태화강 국가정원 관광객 증대에 영향을 미치는 것으로 나타났다"며 블로그 게시를
www.newsis.com
'기타상식 > 국내관광산업' 카테고리의 다른 글
| 2019년 기준 한국 관광산업 현황(2019년 관광사업체 조사보고서) (0) | 2021.02.19 |
|---|---|
| [신문스크랩] 위드 코로나19 시대 여행 키워드 (0) | 2021.01.21 |
| [보도자료] 2020년 한국관광의 별 다섯 곳 (0) | 2021.01.18 |
| [신문스크랩] 국내여행에서 기회 찾는 여행플랫폼 (0) | 2021.01.14 |
| [보도자료스크랩] 2021년 국내관광 전망 (0) | 2021.01.14 |


댓글